I have the money shot for my LCA presentation
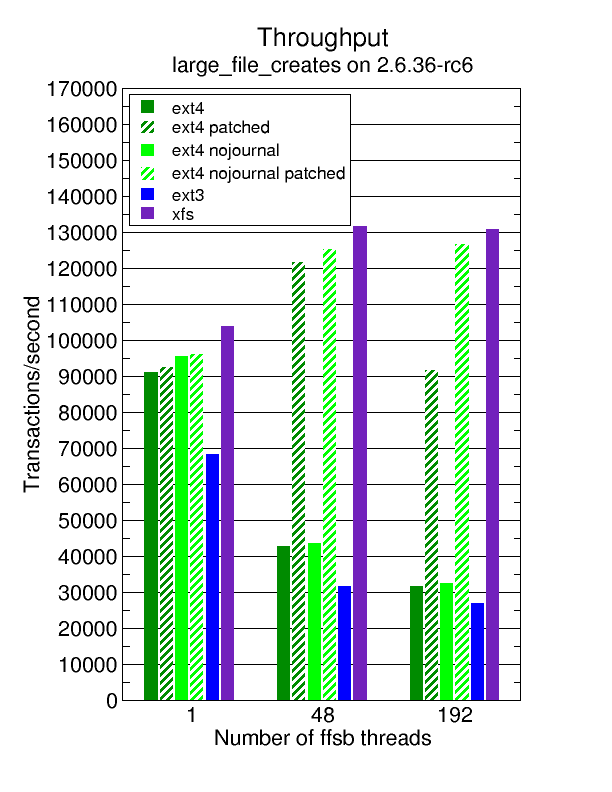
Thanks to Eric Whitney’s benchmarking results, I have my money shot for my upcoming 2011 LCA talk in Brisbane, which will be about how to improve scalability in the Linux kernel, using the case study of the work that I did to improve scalability via a series of scalability patches that were developed during 2.6.34, 2.6.35, and 2.6.36 (and went into the kernel during subsequent merge window).
These benchmarks were done on a 48-core AMD system (8 sockets, 6 cores/socket) using a 24 SAS-disk hardware RAID array. Which is the sort of system which XFS has traditionally shined on, and for which ext3 has traditionally not scaled very well at. We’re now within striking distance of XFS, and there’s more improvements to ext4 which I have planned that should help its performance even further. This is the kind of performance improvement that I’m totally psyched to see!